CAP 的基础了解
前言
该篇文章主要是讲述了分布式系统中 CAP 的基本理解,主要来源是极客时间专栏 从0开始学架构, 有兴趣的可以了解一下。以下的英文原文来自于 CAP Theorem: Revisited
什么是 CAP 理论
CAP 定理又被称为布鲁尔定理。只有在互联和共享数据的分布式系统中讨论 CAP 才会有意义,由此可以看出 CAP 讨论的是对数据的读写操作,它关注的粒度是数据,而不是整个系统。当我们落地实践时,需要将系统内的数据按照不同应用场景和要求进行分类,每类数据选择不同的策略(AP 还是 CP), 而不是直接限定整个系统所有数据都是同一个策略。
C: Consistency(一致性):
A read is guaranteed to return the most recent write for a given client.
对于某个指定的客户端,读操作能保证返回最新的写操作的结果。因为在事务在执行过程中, client 是无法读取到未提交的数据的,有点类似于数据库的 rr 机制, 只有等到事务提交后, client 才能读取到事务写入的数据,而如果事务失败则进行回滚, client 也不会读取到事务中间写入的数据。核心是:保证客户端获取的数据都是最新的。
A: Availability(可用性):
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障节点在合理的时间内返回一个合理的结果(非错误和超时)。 重点是 返回的结果是非错误和超时。
P: Partition Tolerance (分区容忍性):
The system will continue to function when network partitions occur.
当出现网络分区后,系统能够继续“履行职责”。 网络分区导致的原因: 不论什么原因,可能是丢包,可能是链接中断,还有可能是拥塞, 只要是导致了一部分节点和另外一部分无法通信。就通通算在里面。但出现网络故障时:系统还能运行。
设计分布式系统的两大初衷: 横向拓展和高可用性。“横向扩展” 是为了解决单点瓶颈问题,进而保障高并发量下的可用性。“高可用性”是为了解决单点故障(Single Point of Failure – SPOF), 进而保障部分节点故障时的可用性。由此可以看出分布式系统的核心诉求就是可用性,而这个可用性整好是这里的 A。 为了保证可用性,一个分布式系统通常由多个节点组成,每个节点中都维护了自己的数据,为了防止访问不同节点时出现有数据的偏差,就必须保证每个节点的数据的一致性。这个里的一致性正是上文提到的 C.
需要注意的是并没有考虑到数据同步过程中网络耗时的存在,当两个节点A, B进行数据同步的过程中, 节点 A 的数据和节点 B 的数据并不是完全相同,所以在现实中的分布式系统,理论上无法保证任何时刻的绝对一致性,不同业务系统对上述耗时的敏感度也不一样。在极端的严苛的场景下,我们必须保证业务 CA 选项, 可以将某部分业务都在一个系统内,然后根据不同的用户进行分区。
CAP 应用
在分布式系统中, 我们无法保证网络 100% 可靠,可能出故障,分区是一个必然的现象,因此必须选择 P 要素。 在实际设计过程中,每个系统不可能只处理一种数据,而是包含了多种类型的数据,有的数据选择 CP, 有的数据必须选择 AP。如果选择了 P, 那么只可能是单点(子)系统,理论上可以做到 CA。但是单点系统并不是分布式系统,所以并在 CAP 的讨论范围内。在架构设计时, 既要考虑分区发生时选择 CP 还是 AP, 也要考虑分区没有发生时如何保证 CA。
- CP : 一致性和分区容忍性
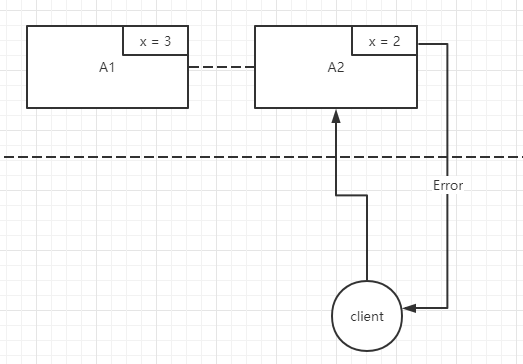
A1 当更新 x 的值为 3 时, A2 此时还是 x = 2, 当 client 去读该系统的 x 值, 按照一致性原则,此时应该返回 Error, 这样就不满足了可用性了。
- AP: 可用性和分区容忍性
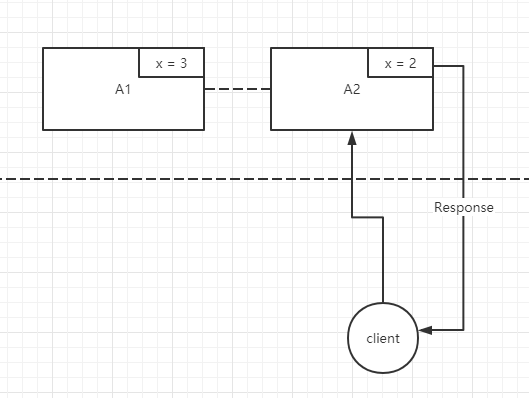
A1 更新 x = 3时, A2 还是 x = 2, 当 client 去读该系统的 x 的值时, 按照 A 可用性来说,此时返回不是应该 error 或者超时,而是一个合理的值 2。
现在系统来说,大部分都会满足 99.99% (4 个 9) 或者 99.999% (5 个 9) 的可用性,因此大部分时间都是可用的,那么我们得考虑分区故障后,怎么才能让系统重新达到 CA 的状态。很多工程上都选择了 AP 并保证了最终一致性,此时用的方式为:人工数据订正和补偿,定时脚本批量检查和修复。
延伸阅读
ACID
ACID 是数据库中概念。 A (Atomicity) 原子性和 CAP 中的 A (Availabity) 可用性意义不同。 ACID 中的 C 表示的是: 在事务开始之前和事务结束以后, 数据库的完整性没有被破坏。即所有改变数据库数据的动作事务必须完成, 没有事务会创一个无效数据状态。 而 CAP 中的 C 指的是 client 端获取服务端的数据都是最新的数据。一个是数据的完整性,而 CAP 中是数据的一致性,还是有一定的区别的。
BASE
- BA : 基本可用 (Basically Available)
分布式系统出现故障时,允许损失部分可用性,既保证核心可用。 在实际生产环境中,怎么区分核心和可以损失的业务,是一项很有挑战的工作。
- S: 软状态 (Soft State)
允许系统存在中间状态,而改中间状态不会影响系统整体可用性。
- E : 最终一致性 (Eventual Consistency)
系统中的所有数据副本经过一定时间后,最终达到一致的状态。
关键词:“一定时间” 和 “最终”。 “一定时间” 和数据的特性是强关联的,不同的数据能够容忍的不一致是不同的。这个时间怎么来的呢?需要根据业务不断的调整,来做个合适的值。“最终” 的含义不是不管时间多长,最终还是达到了一致性的状态。
BASE 理论本质上是对 CAP 的延伸和补充,更具体的说,是对 CAP 中的 AP 方案的一个补充。
PACELC
wiki 百科上解释如下:
It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).
在分布式系统中,当出现 P 时,在 AC 中选择一种,否则(E)当正常运行时, 在延迟(L)和一致性(C)中选择。是 CAP 理论的一种延伸。
