ELK 入门实战(一) - 使用安装 WIN 篇
ELK 主要的使用场景为日志分析和搜索引擎。
那么接下来讲述的是 7.13.3 版本 ELK 在 WINDOWS 机子上的安装。当然还有 mac, Linux, 和基于 docker 的安装,这里不做相应的介绍。
ElasticSearch
下载安装
从官网下载,当前版本为 7.13.3, 下载到自己的合适的位置。解压缩文件,打开文件夹:
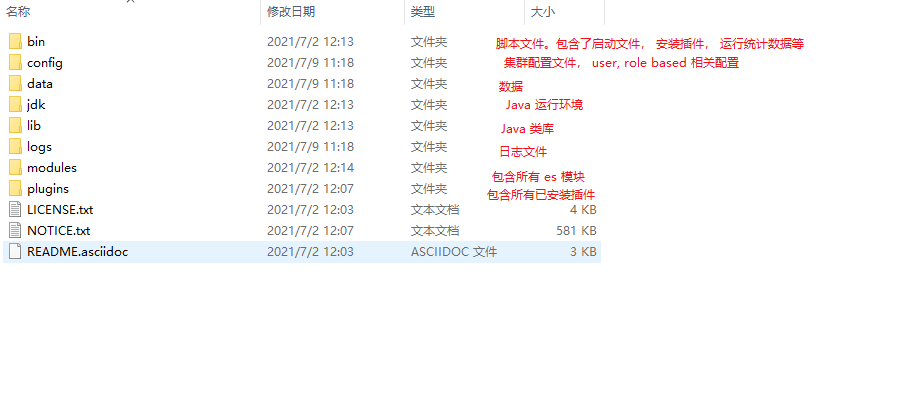
从文件夹中我们可以看到 bin 中包含了启动文件。双击 bin/elasticsearch.bat 文件,将应用跑起来,
[2021-07-09T14:00:29,469][INFO ][o.e.h.AbstractHttpServerTransport] [kaitoshy-WIN10] publish_address {127.0.0.1:9200}, bound_addresses {127.0.0.1:9200}, {[::1]:9200}
[2021-07-09T14:00:29,471][INFO ][o.e.n.Node ] [kaitoshy-WIN10)] started
当 cmd 终端中有这么几行日志时,说明 es 已经启动了。
验证是否安装成功
打开浏览器, 输入地址: localhost:9200, 浏览器中显示为:
{
"name" : "kaitoshy-WIN10",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "js6aXzpiTve6M5OI9ippMg",
"version" : {
"number" : "7.13.3",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "5d21bea28db1e89ecc1f66311ebdec9dc3aa7d64",
"build_date" : "2021-07-02T12:06:10.804015202Z",
"build_snapshot" : false,
"lucene_version" : "8.8.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
高可用
如果需要在开发机上运行多个 Elasticsearch 实例,可以在 ES_PATH/bin 使用以下命令:
.\elasticsearch.bat -E node.name=node1 -E cluster.name=kaitoshy -E path.data=node1_data
.\elasticsearch.bat -E node.name=node2 -E cluster.name=kaitoshy -E path.data=node2_data
.\elasticsearch.bat -E node.name=node3 -E cluster.name=kaitoshy -E path.data=node3_data
可以尝试着用 localhost:9201,localhost:9202, localhost:9203 访问,由于我之前开了 9200 的端口。为什么在一台机器上启动多个节点不需要指定不同的端口呢?在没有绑定 host 的 ip 时, 采取的是 dev mode 启动,这个模式下会在一定范围内分配端口。
ps: 这里需要注意的是当 es 设置为单节点启动时,即在
config/elasticsearch.yml中配置discovery.type: single-node, 后续的节点是起不来的.
后续为了计算机不要太卡,关掉了这个三个节点。
Kibana
下载
输入链接 https://www.elastic.co/cn/downloads/kibana, 由于 es 的版本是 7.13.3, 那么这里下载的版本也需要为 7.13.3 版本。
配置 kibana
解压缩后,打开 config\kibana.yml 文件,修改配置
# 配置 es 节点
elasticsearch.hosts: ["http://localhost:9200"]
# 配置中文
i18n.locale: "zh-CN"
启动
双击 bin\kibana.bat 文件,等待 cmd 启动, 启动后控制台会显示:
log [10:31:15.260] [info][server][Kibana][http] http server running at http://localhost:5601
log [10:31:16.200] [info][kibana-monitoring][monitoring][monitoring][plugins] Starting monitoring stats collection
log [10:31:16.325] [info][plugins][reporting] Browser executable: E:\tools\kibana-7.13.3-windows-x86_64\x-pack\plugins\reporting\chromium\chrome-win\chrome.exe
log [10:31:19.885] [info][plugins][securitySolution] Dependent plugin setup complete - Starting ManifestTask
说明启动完成, 浏览器输入地址:http://localhost:5601,便能查看信息。
启动时如果出现以下错误:
log [00:55:05.950] [error][data][elasticsearch] [resource_already_exists_exception]: index [.kibana_task_manager_1/JoeTE4-ZSLavsAOg2lhrXg] already exists
可以在 cmd 命令行中使用命令:curl -X DELETE http://localhost:9200/.kibana* 删除相应的 index,然后重启即可
检测
安装完 kibana 后,点击左侧菜单栏,找到 Dev Tools,点击后会有 console ,如下图所示
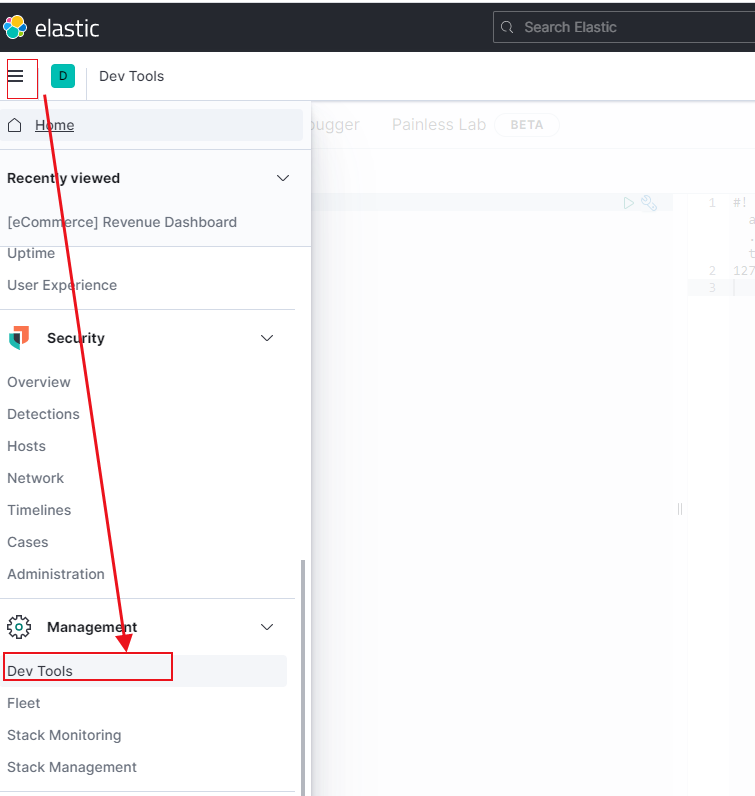
在输入框中输入:
get _cat/nodes
右侧会显示
 即表示节点是正常,但会有 #!的提示,看原因是由于你的集群没有设置秘钥。 如果要设置秘钥请自行查看提示上链接。
即表示节点是正常,但会有 #!的提示,看原因是由于你的集群没有设置秘钥。 如果要设置秘钥请自行查看提示上链接。
Logstash
下载安装
输入网址:https://www.elastic.co/cn/downloads/logstash, 下载 zip 解压缩即可。 用 logstash 导入 cvs 中的数据。
- 下载 MovieLens, 解压缩,目前放在
F:/data-set/ml-25m/中, 这个可以根据自己位置进行修改 - 配置 logstash 的配置文件, LOGSTASH_PATH/config/logstash-movie.conf, 将配置如下
input {
file {
path => ["F:/data-set/ml-25m/movies.csv"]
start_position => "beginning"
sincedb_path => "nul"
}
}
filter {
csv {
separator => ","
columns => ["movieId", "title", "genre"]
}
mutate {
split => {"genre" => "|"}
remove_field => ["path", "host", "@timestamp", "message"]
}
mutate {
split => ["title", "("]
add_field => {"title" => "%{[title][0]}%"}
add_field => {"year" => "%{[title][1]}%"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host", "@timestamp", "message", "content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{movieId}"
#user => "elastic"
#password => "changeme"
}
stdout {}
}
这里需要注意的 movieId, title, genre 这 3 个参数有可能会因为 movies.csv 的版本不一样略有差异,具体是 cvs 中的为准。
- 使用命令
bin\benchmark.bat -f .\config\logstash-movie.conf, 当命令终端不再打印数据时,表示已经完成导入。
Cerebro
说明
cerebro 是一款开源的 elasticsearch 网页端管理工具。 github 地址为:https://github.com/lmenezes/cerebro
下载安装
在 Releases 中,下载 zip 文件解压缩即可。
运行
点击 bin\cerebro.bat 文件,启动后打开浏览器,
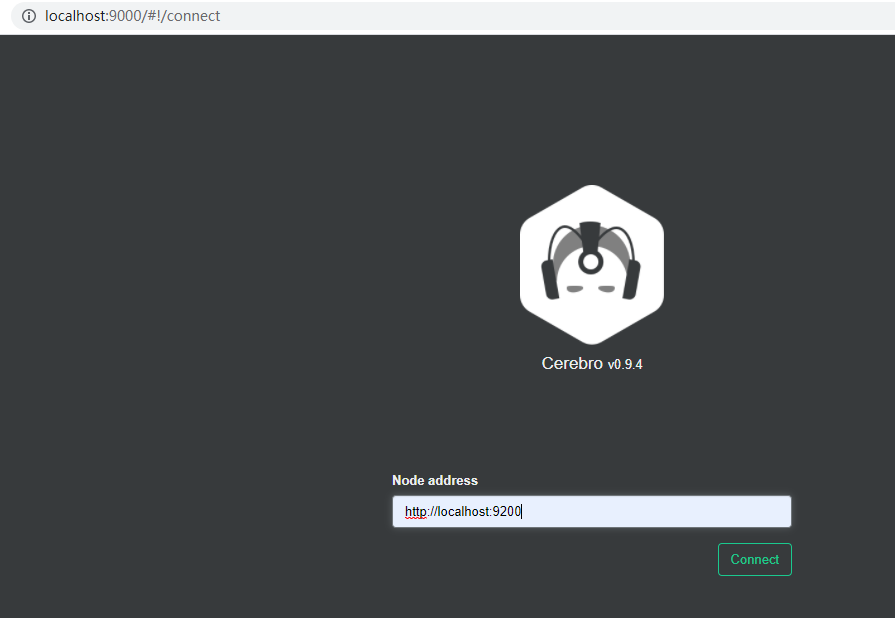
输入要监控的 es 节点后,
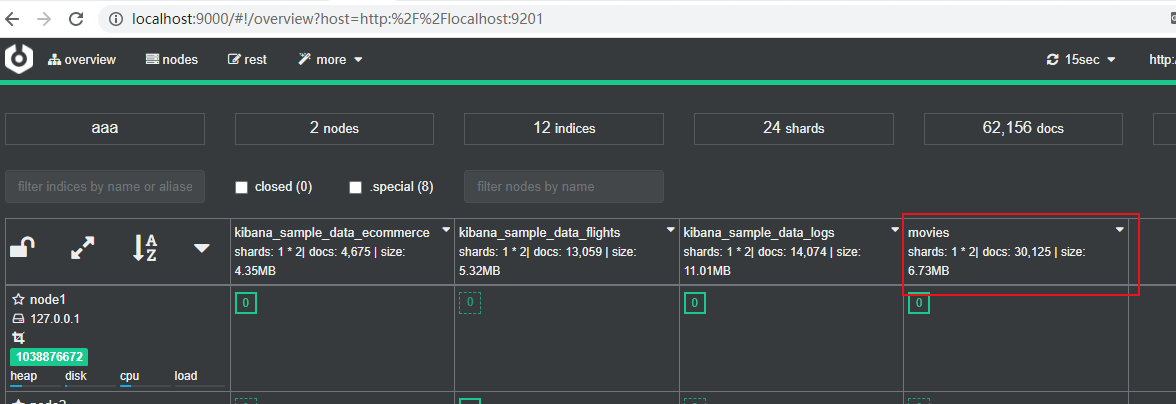
就有相应的数据显示。
